vita_audio_on_vllm
vita_audio_on_vllm
info
vita-audio
https://github.com/VITA-MLLM/VITA-Audio
vllm
https://github.com/vllm-project/vllm
https://zhuanlan.zhihu.com/p/27662961075
vllm document Adding a New Model
https://docs.vllm.ai/en/latest/contributing/model/index.html
Adding a New Model
- Fork the vLLM repository.
- Bring your model code.
- Make your code compatible with vLLM. Initialization Code. Computation Code.
- ( Optional) Implement tensor parallelism and quantization support.
- Implement the weight loading logic.
- Register your model.
- Out-of-Tree Model Integration.
problems
- vita-audio need
pip install funasr omegaconf - predict 10 audio tokens directly from historical inputs and LLM hidden states without requiring additional LLM forward passes
- 权重仓库中模型名填的是Qwen2MTPSenseVoiceForCausalLM
- 注册位置分为Encoder-Decoder 和 decoder only
- export VLLM_LOGGING_LEVEL=DEBUG VLLM DEBUG log 输出
- export PYTHONDONTWRITEBYTECODE=1 禁止使用 pycache
- --disable-frontend-multiprocessing 前端禁用多进程
TODO
Document vllm add a model
Document vita-audio
Repo vllm and PR
run vllm
Qwen/Qwen2.5-1.5B-Instruct work successfully
Qwen/Qwen2.5-7B-Instruct downloading
run vllm multimodal
- Qwen2-audio test
- qwen2-audio web
build vllm from source
run VITA-AUDIO
- where to put weight files? need to change code and set path
VITA-AUDIO model structure, load weights
vllm pytorch implement
vllm inference input and output
implement llm first
then enable multimodal inputs https://docs.vllm.ai/en/v0.6.6/models/enabling_multimodal_inputs.html#enabling-multimodal-inputs
SupportsMultiModal https://docs.vllm.ai/en/latest/api/vllm/model_executor/models/interfaces.html#vllm.model_executor.models.interfaces.SupportsMultiModal
Qwen2AudioForConditionalGeneration https://huggingface.co/Qwen/Qwen2-Audio-7B-Instruct/blob/main/config.json
Qwen2ForCausalLM
https://docs.vllm.ai/en/stable/api/vllm/model_executor/models/interfaces.html
https://docs.vllm.ai/en/latest/design/huggingface_integration.html
VITA-Audio 是一个端到端的 multimodal,是否支持?
qwen2-audio pr https://github.com/vllm-project/vllm/pull/9248
examples/offline_inference/audio_language.py https://vllm-public-assets.s3.us-west-2.amazonaws.com/multimodal_asset/mary_had_lamb.ogg
06-10 -> 06-12
- transformer 学习
- VITA-audio 论文笔记
- obsidian学习?
- 画图?
VLLM
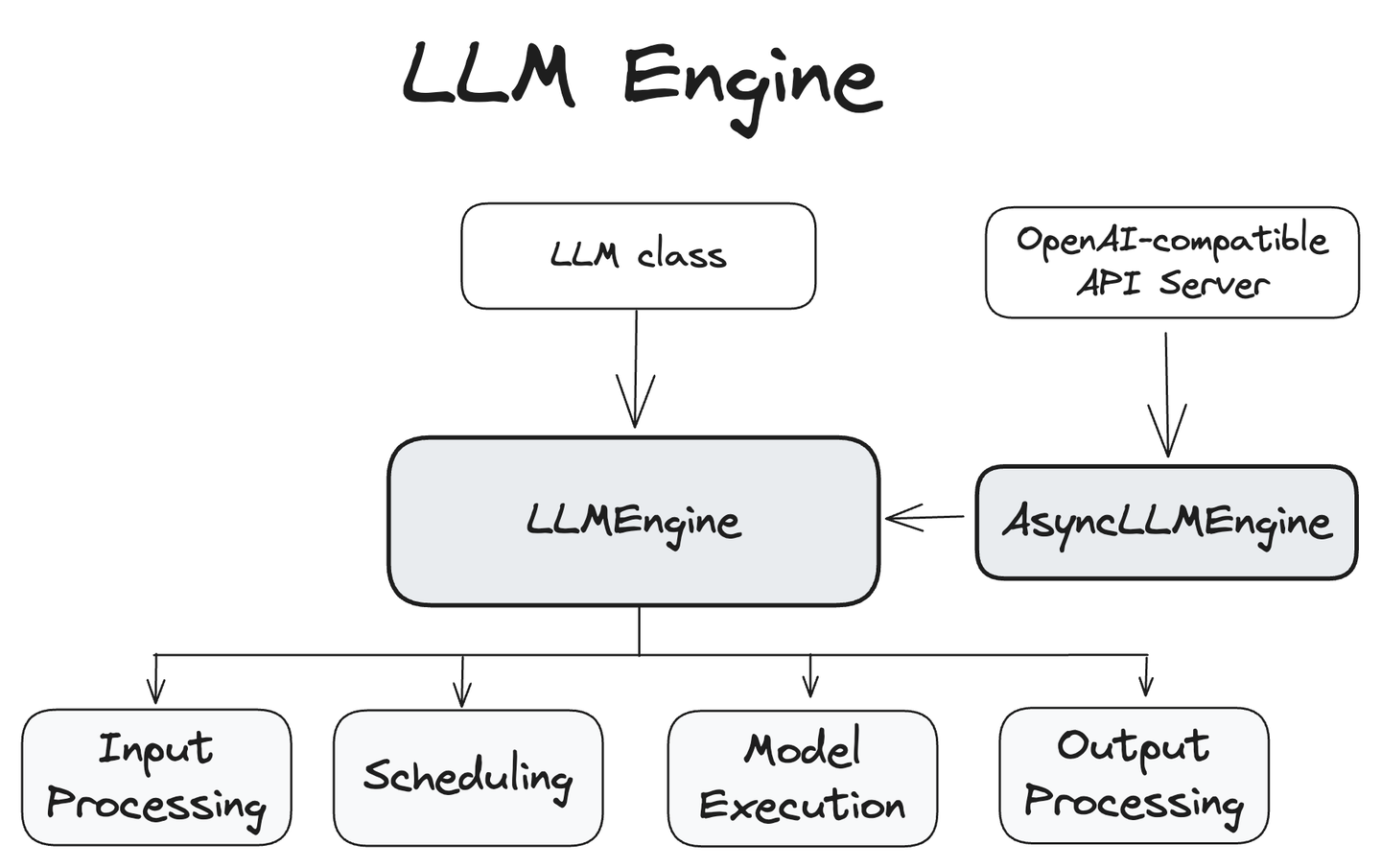
LLM
└── LLM Engine
├── Scheduler
│ ├── Block Manager
│ │ └── Block Allocator
│ │ └── Physical Token Block
│ └── policy
└── executor
└── worker
├── Cache engine
│ └── KV cache Tensor
└── Model Runner
└── model